
Within the modern Azure Data Platform landscape we’re ingesting all relevant data to Azure Data Lake for answers on questions we don’t know yet. In this blog I’ll show you how to get the data that is stored within Azure Data Lake Storage into a schematized SQL store, dynamically, based upon metadata.
The query challenge
Nine times out of 10 we store the data as Apache Parquet file in the Data Lake since it provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk for downstream processing.
The parquet data files are excellent for processing because of the rich compatibility with the Azure Data Services (and other systems that can handle this open source file format). However this format is not easy to query by the typical Data Analyst role within your organization. For this reason we need a SQL data store, like Azure SQL Database, to sink the data so the Analyst will be able to query the data with T-SQL or Power BI.

Solution
The big difference between sinking data into a Data Lake versus a relational data store like SQL is that we need a schema when writing the data to the sink. As a starting point for this solution we need the whole process to be metadata driven to cut development time and standardize the data flow to the sink. In the “SQL Server Integration Services (SSIS)-age” we generated a SSIS package per table to do so, based upon a metadata store.
In the modern age we do this a little bit different, we built one generic data pipeline in Azure Data Factory and manipulate the source, activities and sink at run-time based upon metadata on the specific DTAP-environment. I like to call this the online metadata approach.

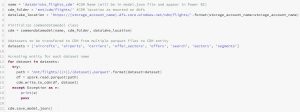
Luckily for us we can do this fairly easy with a dynamic Azure Data Factory pipeline. The pipeline is going to loop over every available table and dynamically set the sink schema based upon metadata.
1-Control-Schematize

2-Schematize

You can clone the solution from my git repository.
Concluding
This is a powerful nugget which shows you how to deal with Data Lake data, how to schematize this data by embracing the “online metadata” approach to ultimately cut DEV and OPS time.

Great content, but your images are gone, can you put them back again?
Thanks for letting us know! We will check it out and fix it.
Still no pictures?